這邊就是先把我們需要的文件做一次indexing ,把需要的文件轉成向量存入db,可以參考Day9 如何實作,在FastAPI我們就以原先配置DB連線設定,並且轉成API方式可以讓各位自己丟檔案,並且使用pypdf及PyPDFLoader 可以真正的讀取pdf文件!
以下為indexing程式:
先安裝新的兩個套件
pip install python-multipart
pip install pypdf
並且實作一下indexing的API~
@app.post("/indexing")
async def indexing(file: UploadFile = File(...),):
embeddings = OpenAIEmbeddings()
vectorstore = PGVector(
embeddings=embeddings,
collection_name="programers",
connection=CONNECTION_STRING,
use_jsonb=True)
temp_file_path = file.filename
try:
with open(temp_file_path, "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
loader = PyPDFLoader(temp_file_path)
docs = loader.load()
os.remove(temp_file_path)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore.add_documents(docs)
return {"upload": file.filename}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
最後放個愛因斯坦的wiki來執行結果
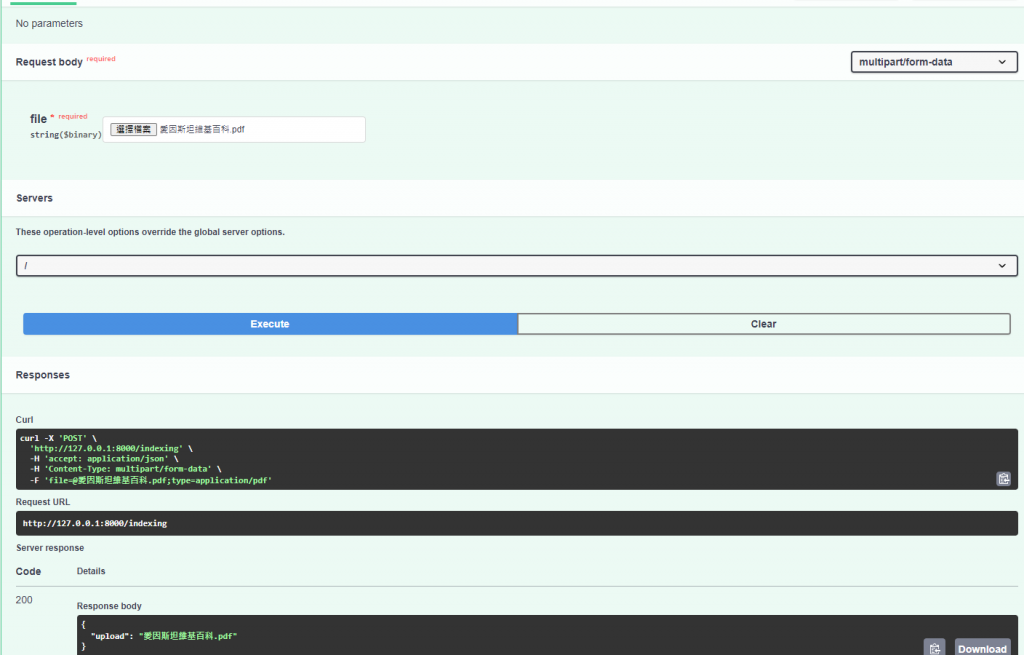

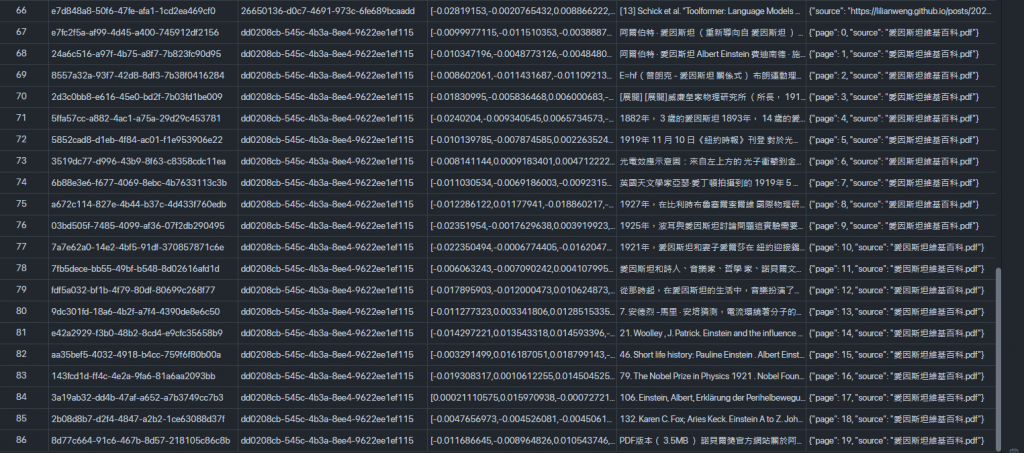
基本上DB有我們的數據了~
最後就是把Day12 LLM的串接API方式做最後的完善!把整個鏈都串起來!
以下為增加檢索(Retrieval)完善llm api程式:
@app.post("/chat")
async def chat(message: str):
try:
retriever = vectorstore.as_retriever()
chain = (
{"context": retriever | _format_docs, "message": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
response = chain.invoke(message)
return {"response": response}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
最後來問一下問題看一下我們的AI回答的如何
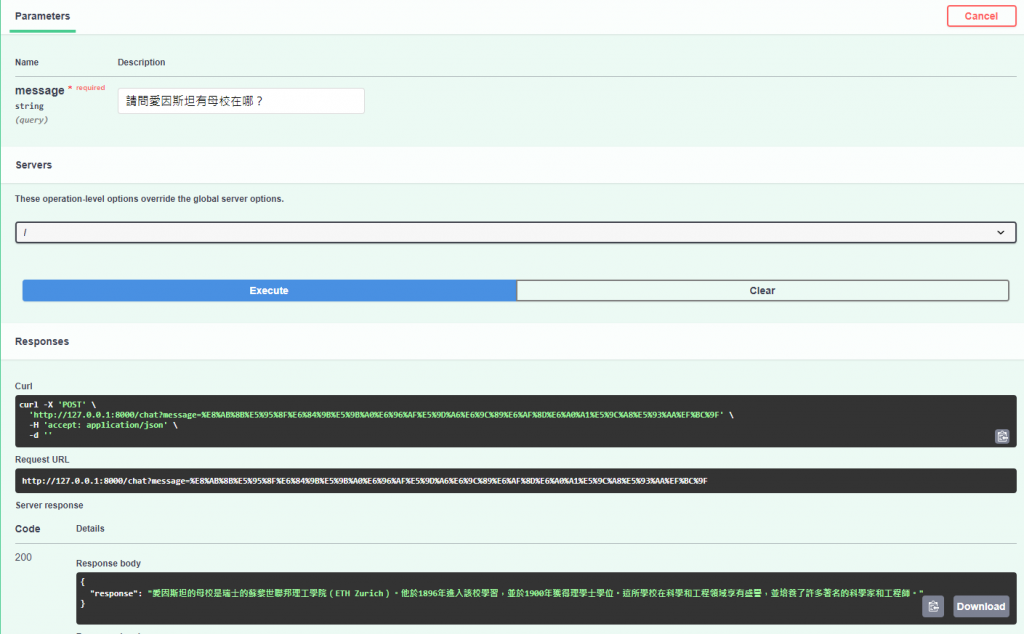
看來有照著我的db去讀取相關資訊出來!大成功!
最後整理一下我的程式碼XD(上面api部份東西抽出來)
import shutil
from fastapi import FastAPI, File, HTTPException, UploadFile
import os
from langchain_community.document_loaders.pdf import PyPDFLoader
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.prompts import PromptTemplate
from langchain_postgres import PGVector
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
app = FastAPI()
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
CONNECTION_STRING = "postgresql+psycopg://benson:benson@localhost:5432/postgres"
prompt = PromptTemplate.from_template("你是專業工程師 ,根據以下內容{context},幫我回答以下問題 {message}:\n")
llm = ChatOpenAI(model='gpt-4o-mini')
embeddings = OpenAIEmbeddings()
vectorstore = PGVector(
embeddings=embeddings,
collection_name="programers",
connection=CONNECTION_STRING,
use_jsonb=True)
@app.post("/chat")
async def chat(message: str):
try:
retriever = vectorstore.as_retriever()
chain = (
{"context": retriever | _format_docs, "message": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
response = chain.invoke(message)
return {"response": response}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/indexing")
async def indexing(file: UploadFile = File(...),):
temp_file_path = file.filename
try:
with open(temp_file_path, "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
loader = PyPDFLoader(temp_file_path)
docs = loader.load()
os.remove(temp_file_path)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore.add_documents(docs)
return {"upload": file.filename}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
def _format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
是不是在地端能做一個自己的RAG系統是一件很簡單的事呢!後續會把這套系統配合GCP的方式部署到雲端上,讓各位都可以做使用,後續就會介紹雲端元件,依照後續章節也會迭代調整程式碼!
各位要好好看完!我後續在某一天會把這個git實作開源出來XD

